Just one more column, what could go wrong?
- dazfuller

- May 22, 2021
- 3 min read
Sometimes, when you go scanning through the documentation for Spark, you come across notes about certain functions. These tend to offer little hints and tips about using the function, or to give warnings about their usage.
One of these functions is the DataFrame withColumn function. Taken as of the Spark 3.1.1 documentation the note on it reads.
This method introduces a projection internally. Therefore, calling it multiple times, for instance, via loops in order to add multiple columns can generate big plans which can cause performance issues and even StackOverflowException. To avoid this, use select() with the multiple columns at once.
But these seems such a harmless little function, that just simple tells Spark that we'd like to add a new column based on some expression. So what exactly is it doing?
The introduction of a projection is similar to a select statement in SQL, it takes the columns and expressions requested and presents them as columns. This way any subsequent operations can refer to the new projected column.
For example, if we takethe following code.
df = (spark.read.table("staging.landreg_price_paid")
.withColumn("deed_date_year", year("deed_date"))
.withColumn("deed_date_month", month("deed_date"))
.withColumn("postcode_outward", element_at(split("postcode", " "), 1))
.withColumn("postcode_district", regexp_extract("postcode_outward", "\w+\d+", 0)))
for i in range(0, 11):
df = df.withColumn(f"col_{i}", lit(0).cast("double"))
df.explain(extended=True)This is reading in from an existing table, adding some new columns (where postcode_district depends on postcode_outward), and the adds in another 10 column, just to simulate a process where we're adding in extra columns later on. Finally this is calling "explain" to show the various stages of the execution plan.
And the resulting execution plans? Well they look like this.

If you can read the plans then you'll notice that by the time we've gotten to the Optimized and Physical plans Spark has managed to optimize out all of the Projections. This is great because it means that it's not doing all of that work when it's actually executed. But it's also not so great as Spark has had to spend time optimizing all of that out! Hopefully you can see how, if there were even more of these, we'd eventually get to a situation which would result in the overflow exception errors mentioned in the note.
So what can we do instead? Well in the note it says that we can use a single Select statement with all of the columns instead. And we can do that by exploding our our additional comments, and with a little refactoring to get it to look like this.
cols = [lit(0).cast("double").alias(f"col_{i}") for i in range(0, 11)]
df2 = (spark.read.table("staging.landreg_price_paid")
.select(
"*"
, year("deed_date").alias("deed_date_year")
, month("deed_date").alias("deed_date_month")
, element_at(split("postcode", " "), 1).alias("postcode_outward")
, regexp_extract(element_at(split("postcode", " "), 1), "\w+\d+", 0).alias("postcode_district")
, *cols
))
df2.explain(extended=True)Here we're using a single select statement that selects all of the existing columns (the wildcard character), our new columns with a little repetition, and all of the new columns by using the unpack operator (or "splat" which I think is a much better name).
So, does this make a difference to the execution plans? Well lets have a look.
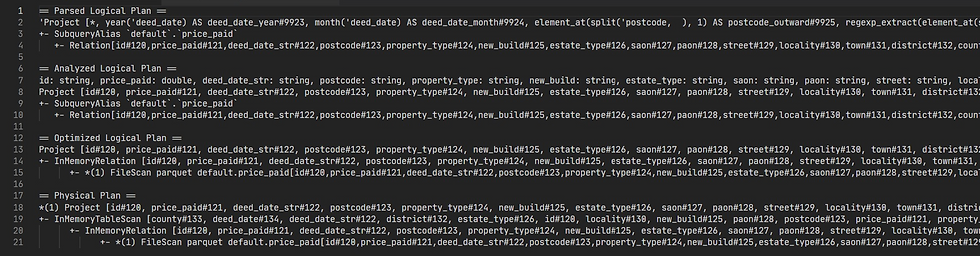
Without even reading it this is looking a lot better. We're still arriving at an Optimized and Physical plan which are pretty much the same as before, but our Logical plans are much smaller, meaning that the optimizer has much less work to do. As you can see in the image they now only contain a single projection which is the expected output of the query. This means we're now much less likely to run into the stack overflow exception mentioned in the withColumn note.
But is there a performance impact to this as well? I ran both sets on a Databricks 8.2 Runtime, which provides Spark 3, several times and took the best time from each set. With all of the withColumn statements the best run time was 2.22 seconds, and using the single select statement this came down to 0.62 seconds. So we're removing potential issues and improving performance as we go.
So should we always avoid the withColumn statement? Well not really as it's still an incredibly useful function. In the improved example above you can see I'm repeating myself with the code for postcode_outward, so we could improve this by using a single withColumn statement and then using that in the select. Or when we're reading in files it can be useful to add a withColumn statement to append the input file name. The key is to reduce our usage of withColumn to only those times when it's necessary, and if we're doing a lot of transformations - either directly or in a loop - then we should look at alternatives instead.

Born in South Africa and raised in Basel, Switzerland, link Norbert is the fourth Norbert in his family. His great-grandfather started a family tradition of gifting watches, and Norbert received his TAG Heuer Link Calibre 16 Chronograph from his parents when he link graduated high school. It’s a constant reminder of all his link parents have done for him.
Oh, and want to know a really big reason jewel counts are on every movement – down to the lowliest zero (0) jeweled link quartz movement? To import a watch into the USA the movement is actually required to have a jewel count stamped on it – and there are different link import duties depending on link the number of jewels, too (this means functional jewels, not decorative ones).
While it's become a bit of a shortcut for many small watchmakers to link take pay tribute to vintage Patek Philippe watches, and rare steel ones especially to generate some buzz, link Rexhepi manages to take inspiration from this same era, but link in a way that never feels corny.
Looking back, I've rushed into things and bought watches that weren't right for me. In the early days, from 2012 to link 2014, I spent a lot of money on things trying to find joy in life. She was in her early 20s, just out of university. "My education back then was 'This is link pretty! This link is nice!'" Thun says. "And I hope that the salespeople have .001 guilt about making me blindly buy things that didn't suit me and not educating me."
The watch on offer today was produced in 1969 but was awarded for the 1974 Cotton Bowl Classic. Among the Cotton Bowl watches from the crown and its sister brand, these "Jumbo" Date + Day examples are arguably the best. I would say it is a toss-up link between the Rolex Datejusts (1969, 1970) and the Date + Day Tudors (1974, 1976). The dial design is really fascinating as all Tudor link text has been omitted to make room for link the large Cotton Bowl logo, year, and arched text at six o'clock.